
Industry:
Logistics
Technology stack:
Our client is a prominent player in the logistics industry, with a global presence and a reputation for excellence. As a logistics provider, the company offers a wide range of services to meet the needs of its diverse clientele. These services include sea, air, and road freight transportation, as well as contract logistics and integrated logistics solutions.
Our client's legacy on-premises system for logistics management and tracking of goods movement was struggling to keep up with the rapidly changing business landscape. With new vehicle sensor types emerging and evolving business processes, a significant portion of analytics required manual or batch processing. Meanwhile, global standards for modern parcel tracking and vehicles were demanding real-time data processing.
To address these challenges, our client recognized the need to design a cloud-agnostic solution that could meet their business needs and non-functional requirements. They needed a system that could handle large volumes of data and provide near real-time insights to support critical decision-making.
The new solution would need to be flexible and scalable, accommodating changes in data sources, business rules, and reporting requirements. It would also need to integrate seamlessly with the existing systems and be easy to use for both technical and non-technical users. By implementing a cloud-agnostic solution, our client would have the flexibility to choose the cloud provider that best suited their needs and take advantage of the latest cloud technologies. This would ensure high availability, scalability, and performance while reducing the need for expensive hardware and infrastructure.
The Divectors team proposed a brand-new cloud-based data processing solution for the client, which included an MVP implementation. The team made key decisions during the system design phase to ensure the solution met the client's needs and was future-proof.
To leverage the client's existing AWS resources, the team decided to use Amazon Web Services as the cloud provider. They also chose to use Airflow for process orchestration, which is represented in AWS as MWAA and can be deployed on other clouds using Kubernetes services. For transparent system audit and logging, the team decided to use a combination of AWS CloudWatch and DataDog. To support data exploration and analytics workloads, the team recommended introducing a new data warehouse (DWH) on Snowflake as a centralized storage for structured and processed information. The DWH would also store "raw" data in the staging layer.
To implement data processing, the team recommended using a set of data pipelines built on top of dBt models and embedded Jinja templates. The centralized DWH would serve as a data source for other repositories but may not be effective for product requests with fast response time requirements.
To ensure infrastructure consistency and to enable easier maintenance, the team decided to deploy the solution as Infrastructure as Code, using Terraform. Finally, the team recommended implementing CI/CD via AWS CodeBuild.
The proposed solution is depicted in the diagram below, which shows that ingesting processing can be performed using a combination of Airflow and dBt, with Snowflake serving as the centralized data repository.
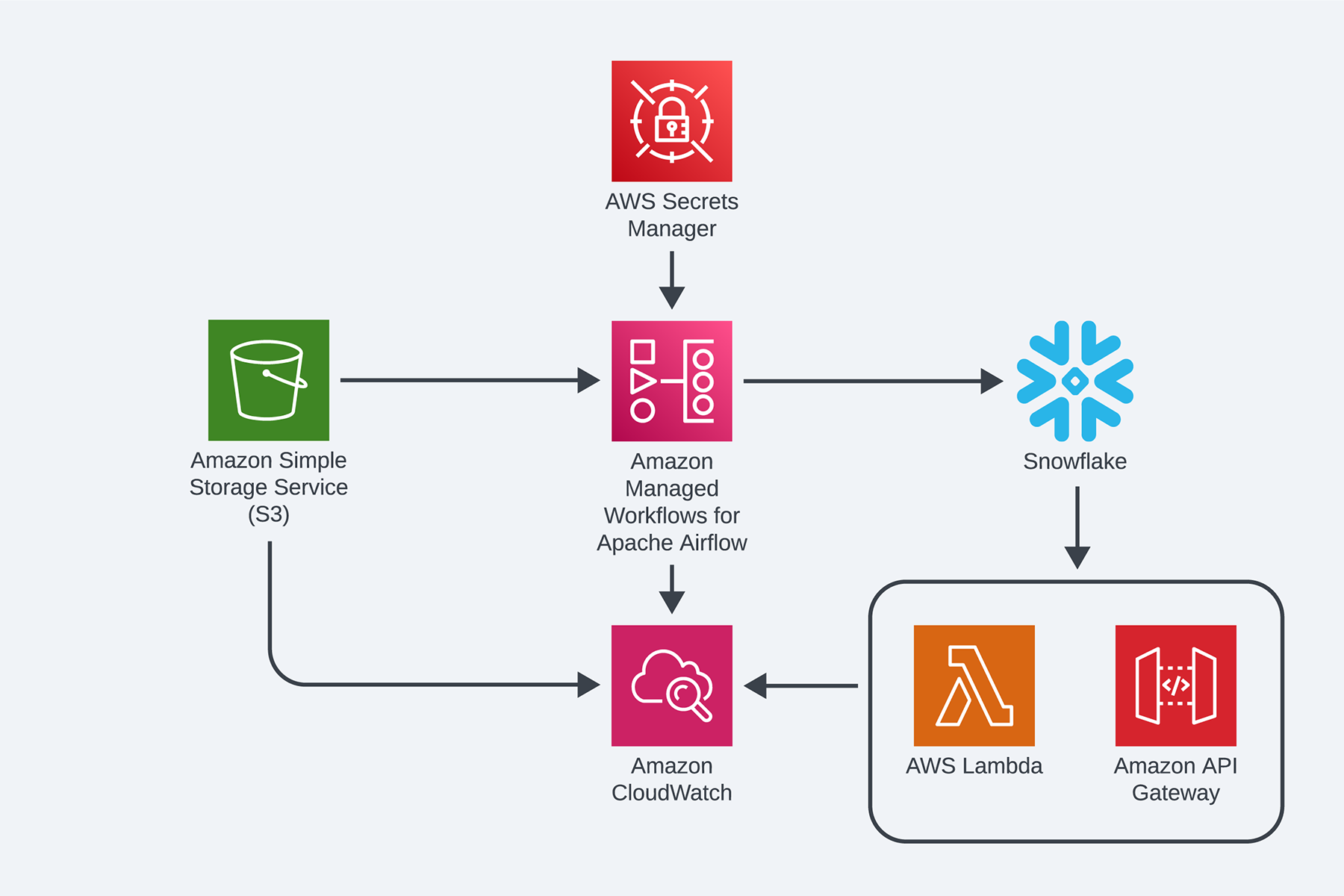
The implemented solution is fully cloud-based and has successfully met the defined SLAs, RTO, and RPO, ensuring business continuity and availability of services. The solution also provides transparent, detailed operational audit and reporting for MVP platform activity, enabling better monitoring and control.
One of the key advantages of the solution is its ability to provide scalability and maintain data integrity from different data sources to the Snowflake analytical engine. This allows the client to integrate new data sources and scale up the system as their business needs evolve.
The solution has been standardized and deployed using Infrastructure as Code (IaC) principles, making it easy to replicate and use by different divisions for satisfying various business needs from reporting and data analytical perspectives.
The implementation of data pipelines and automation has significantly increased the efficiency of analytics data processing, reducing the need for human intervention in the data processing process. This has not only improved the speed of data processing but also reduced the potential for human error, ensuring data accuracy and reliability.
Overall, the solution has provided our client with a modern, scalable, and efficient cloud-based data processing system, which has improved their ability to manage logistics and track goods movement in real-time.
It also provides a foundation for future improvements and innovations, ensuring our client remains competitive and can quickly adapt to changing business needs.
Director of Data Analytics, Logistics Company