Simplifying Analytics and Data Pipelines with DBT (Data Build Tool)
The landscape of data analytics has undergone significant transformations, adapting to the ever-growing data needs of businesses. In this evolving space, tools that simplify and streamline data operations are invaluable. Enter dbt (Data Build Tool), a solution designed to enhance and simplify data analytics workflows.

Understanding dbt in Data Analytics
What is Data Build Tool (dbt)?
DBT, or Data Build Tool, represents a paradigm shift in the data analytics arena. It is a command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. Born from the need to manage increasingly complex data transformations, dbt offers a way to leverage the power of modern data warehouses to run transformations.
Definition and basic concept of dbt in the context of data analytics.
DBT is primarily used to streamline data pipelines and analytics processes. It allows for the creation of complex data models, testing, and documentation. Real-world applications range from small startups organizing their first data models to large enterprises managing intricate data systems.
Historical context and development of dbt.
Initially, data analytics involved complex, often cumbersome processes managed by specialized IT departments. Early tools were heavily focused on Extract, Transform, Load (ETL) operations, where data was extracted from various sources, transformed into a suitable format, and then loaded into data warehouses. These processes were generally time-consuming and required significant technical expertise.
The advent of modern data warehouses like Snowflake, Google BigQuery, and Amazon Redshift transformed the data analytics space. These technologies offered scalable, cloud-based solutions capable of handling vast amounts of data. However, there was still a gap in efficiently transforming this data within the new cloud warehouse paradigm.
DBT was created to fill this gap. Developed by Fishtown Analytics (now dbt Labs), it was designed to empower data analysts to transform data in their warehouses without the need for complex, engineer-driven ETL pipelines. The idea was to bring the transformation process closer to the data, leveraging the power and scalability of modern data warehouses.
What is dbt Used For?
DBT as it’s inventors call it – it is a latter T, in abbreviation ETL. Via writing simple SQL statements, It allows for the creation of complex data models, testing, and documentation. Real-world applications range from small startups organizing their first data models to large enterprises managing intricate data systems.
Overview of dbt’s functionalities in data pipeline and analytics.
- SQL-Based Transformations: dbt allows users to write custom transformations in SQL, the language familiar to most data analysts. This approach simplifies the process of transforming raw data into meaningful insights.
- Incremental Processing: It supports incremental data loading, reducing the time and resources needed for data processing. This is especially beneficial for large datasets.
- Reusable Models: dbt enables the creation of reusable data models. These models serve as the building blocks of data transformation, promoting consistency and efficiency.
- Integration with Git: dbt integrates with version control systems like Git. This integration ensures that changes to data models are tracked, enabling better collaboration and history tracking.
- Data Testing: dbt provides functionalities for data testing, ensuring the accuracy and integrity of data models. Users can write custom tests to validate their data transformations.
- Automated Test Execution: Tests can be automatically executed as part of the data pipeline process, ensuring ongoing data quality.
- Automatic Documentation Generation: dbt automatically generates documentation for data models, making it easier to understand and communicate the data architecture.
- Web-based Documentation Interface: The generated documentation is accessible via a web interface, facilitating easy access and navigation.
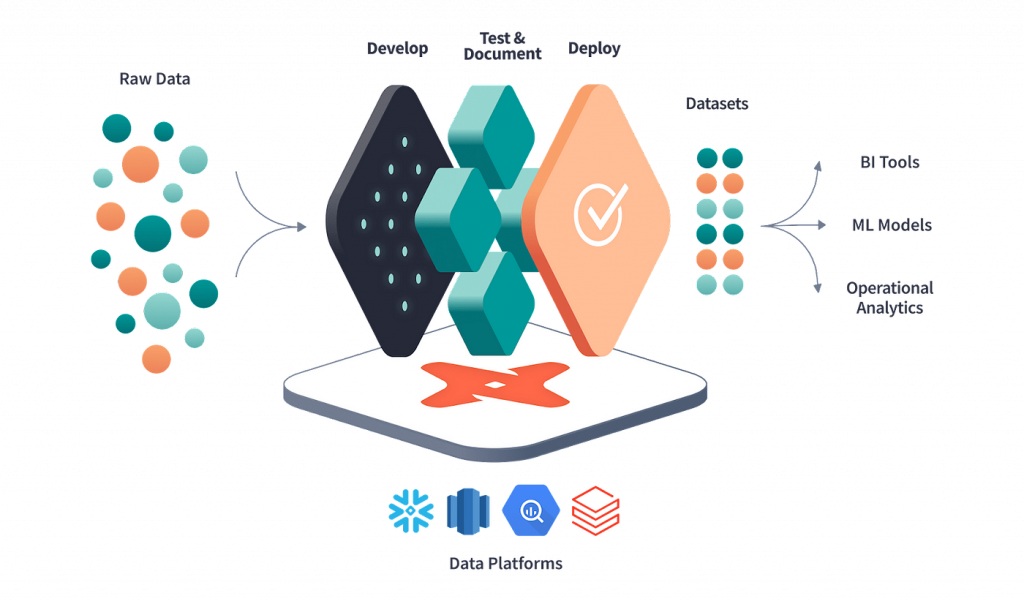
Core components of DBT
DBT (Data Build Tool) is built around several core components that form the foundation of its functionality. These components work together to provide a comprehensive environment for data transformation and analytics. Understanding these core components is crucial for effectively utilizing dbt in data pipelines.
Models
- Models are the primary building blocks in dbt. They are SQL queries that define the transformations to be applied to your raw data, turning it into meaningful, analytics-ready data.
- Models can range from simple select statements to complex analytical transformations. They are stored as individual files in a dbt project and can reference other models, creating a modular and maintainable data transformation workflow.
Sources
- Sources in dbt represent raw data tables or views in your data warehouse.
- By defining sources, dbt can track where data is coming from, helping maintain the lineage and transparency of data transformations. It also facilitates testing and documentation by providing a clear starting point for data pipelines.
Tests
- Tests in dbt are assertions about your data, ensuring its quality and integrity.
- Common tests include checking for null values, uniqueness of key fields, and referential integrity. These tests are run against the transformed data to catch issues early in the data pipeline, ensuring reliability and accuracy.
Documentation
- Documentation is an integral part of dbt’s functionality, providing insights and information about the data models and transformations.
- dbt auto-generates documentation from the model SQL files and their descriptions. This documentation can include information about sources, models, tests, and their dependencies, making the data transformations transparent and understandable for all stakeholders.
Seeds
- Seeds in dbt are CSV files that can be loaded into your data warehouse.
- Seeds are useful for managing small pieces of static data, like mapping tables or parameters, which can be used within your dbt models. Seeds help in managing data that doesn’t change frequently and needs to be version-controlled.
Snapshots
- Snapshots capture the state of a dataset at a given point in time.
- This feature is used for data that changes over time (slowly changing dimensions), allowing users to track historical changes to their data and understand how it evolves.
Packages
- Packages are collections of dbt configurations, models, tests, macros, etc., that can be shared and reused across dbt projects.
- By using packages, dbt users can leverage pre-built components and integrations developed by the community, enhancing the functionality and efficiency of their data pipelines.

Advantages and Disadvantages of dbt
Advantages of dbt
SQL-Friendly: dbt allows data analysts to write transformations in SQL, a language they are already familiar with. This reduces the learning curve and increases productivity.
Modularity and Reusability: The modular structure of dbt makes it easy to reuse code and models, improving maintainability and consistency across data projects.
Version Control Integration: dbt’s integration with version control systems like Git ensures that all changes are tracked, promoting collaboration and accountability.
Automated Testing and Validation: dbt supports testing of data models, ensuring data quality and integrity. This automated testing framework is crucial for reliable data pipelines.
Documentation: Automatic documentation generation helps maintain clear and up-to-date documentation, essential for understanding and auditing data transformation processes.
Scalability: dbt is designed to work efficiently with large datasets in modern cloud data warehouses, making it a scalable solution for growing data needs.
Community and Ecosystem: Being open-source with a strong community support, dbt benefits from continuous improvements, shared knowledge, and a wide range of community-contributed packages and plugins.
Disadvantages of dbt
SQL Dependency: While being SQL-friendly is an advantage, it also limits dbt to transformations that can be expressed in SQL, potentially excluding more complex data operations.
Learning Curve: Despite its SQL-centric approach, there is still a learning curve associated with mastering dbt’s specific syntax, concepts, and best practices.
Limited ETL Capabilities: dbt is specifically designed for the “transform” part of ETL (extract, transform, load) and relies on other tools for extraction and loading, which might require additional integration efforts.
Resource Intensive for Large Datasets: Although scalable, dbt can be resource-intensive when dealing with very large datasets, potentially leading to increased costs and performance considerations in cloud environments.
Limited GUI: dbt’s primary interface is command-line, which might not be as user-friendly for those who prefer graphical interfaces for data operations.
Dependency on Cloud Data Warehouses: dbt is optimized for cloud-based data warehouses, which may limit its utility for organizations relying on traditional, on-premise databases.
Conclusion
The integration of dbt within modern data pipelines underscores a transition to more agile, collaborative, and scalable data practices. Its compatibility with cloud-based data warehouses caters to the growing demand for flexible and powerful data processing solutions. This synergy allows organizations to harness the full potential of their data assets, leading to more informed decision-making and strategic insights.
If you have any questions or want to start building you data analytics on top of DBT, please contact us.

